
Intro
프로젝트 기간 - 2022.03 ~ 2022.10
회고를 왜 이제와서 하고있는지는 모르겠지만 포트폴리오 정리하려고 과거 흔적을 보다보니 한군데 정리해두고싶어져서 이제라도 쓰기로했다. 그래도 블로그 말고 다른곳에 잔해들이 많이 남아있어서 다행 (진작 포스팅 할걸 그땐 생각을 못했다..)
해당 플젝은 내가 본격적으로 들어간 첫 대규모 프로젝트였다.
프로젝트 진행이 재미있긴 했다. 해보고 싶었던거 다 해보고 레거시를 뜯어고치고, 최신기술 도입하고 ㅋㅋㅋ
그래서 이번에는 시스템 설계를 어떻게 했었는지에, 왜 그렇게 했는지에 대한 글을 써보고자한다.
제로베이스에서 프로그램을 만든건 아니고 내가 들어갔을 때, 기존 시스템이 있었는데 코드퀄리티와 너무 많은 오류율로 인해 제대로 작동이 불가능한 상황이었어서 새로 아키텍쳐 구축부터 해야하는 상황이 생겨버렸다. ( + 비용문제와 하드웨어 변경 이슈) 처음엔 서버만 변경하려했는데 갑자기 빠른시일안에 모든걸 바꿔야한다는 명을 받게됨😂
Architecture 설계
일단 제일 시급했던게 기획자가 없다. 플로우 차트? 기능 정의서? 없다. 그..그래.. 없으면 뭐 하면되지 뭐!
우선 여러번의 회의와 수정에 수정을 거듭해 요구사항을 도출해서 요구사항 정의서를 만들었다. 그리고 이를 바탕으로 기능을 정리하고 미로에 스토리보드를 작성해 아래와같은 시나리오를 만들었다.

이제 아키텍쳐를 설계한다.
아이패드에 그때 썼던 노트를 보니 고뇌가 보인다.
우선 프로그램은 이렇게 나누었다.
- service api server
- object recognition server
- face recognition server
- 키오스크 프로그램
- back office
- sub website
추론이 필요한 기능이 두개가 있었는데 각각이 완전히 독립적이며 둘다 상당히 많은 리소스를 차지하는 관계로 서버 두개로 쪼갰다.
대부분의 비지니스로직을 가지고있는 service api 는 Nest.js + typescript 조합으로 구현했다.
db는 MySQL과 MongoDB 고민 하다가 아무래도 결제정보와 고객정보가 있다보니 정형화된 데이터가 나을것 같고 안정성 측면에서도 더 나을 것 같아서 선택했다.
키오스크서버와 back office 의 서버는 하나로 쓰기로 했다. 개발 인원이 많은것도 아니고 겹치는 api가 있을것이라 판단해 하나의 서버로 결정했다.

DB 설계
중심이 되는 테이블과 칼럼부터 관계를 작성해나갔다.
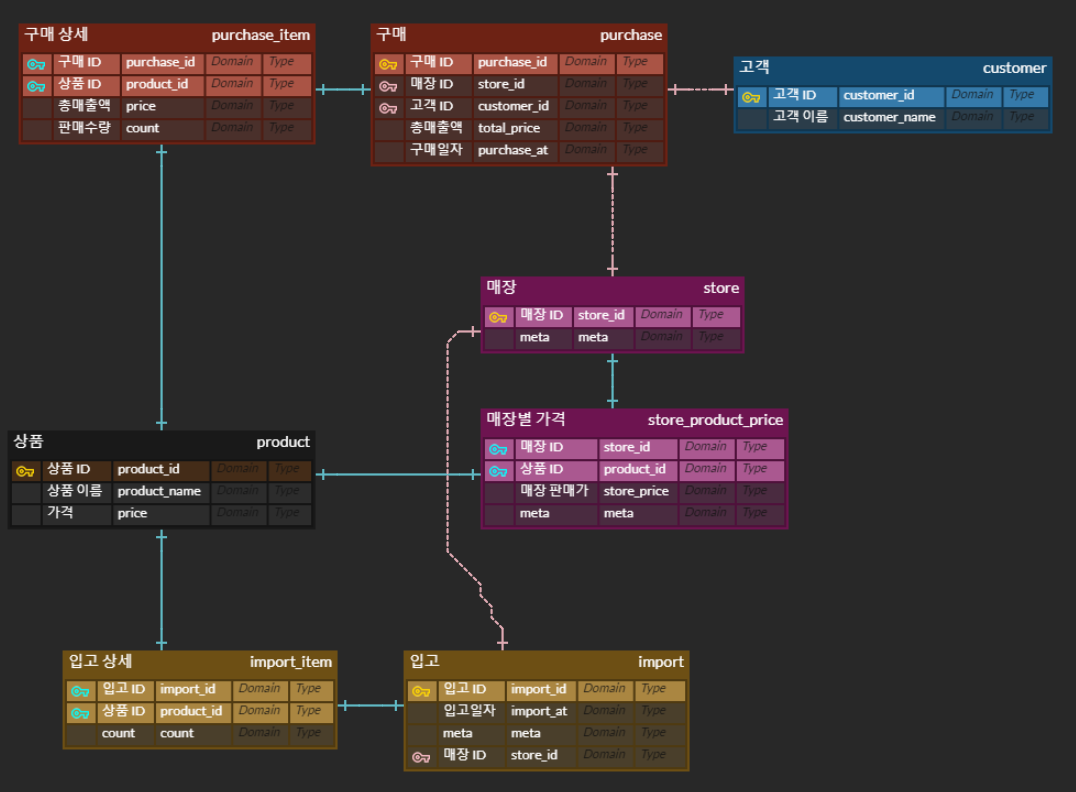
구축했던 DB ERD를 기반으로 극히 일부분만 변형해서 블로그 포스팅용으로 새로 정리해보았다.
구매 테이블은 고객이 한번에 구매한 전체 상품에 대한 정보를 나타낸다. (영수증 하나 라고 생각하면 편할듯)
이 테이블은 구매한 매장이 어디인지를 나타내는 매장 ID와 누가 구매했는지에 대한 고객 ID를 Non Identifying으로 포함한다.
구매 상세 테이블은 해당 영수증에 찍혀있는 상품을 나타낸다. 예를들어 몽쉘 2개면 몽쉘 ID랑 위 영수증 ID를 복합키로 하고 count 는 2인 구매 상세 데이터가 생기는것이다.
매장별 가격 테이블이 따로 있는 이유는 기본적으로 등록된 상품의 가격과 매장별로 점주가 판매하려는 가격이 다를 수 있기 때문이다.
입고는 구매와 같은 프로세스다. (상품이 들어오냐 나가냐의 차이일 뿐)
ERD보니까 이거 설계하는 시기에 PG사 어디쓰냐, 하드웨어 어디쓴다, 얼굴인증 이거쓸까 이러면서 회의 엄청 불려갔었던 기억이 나네..
API 설계
서버는 아키텍쳐에 대한 정의를 제공하는 Nest.js 사용. 아키텍쳐의 정의를 제공하기 때문에 개발할 때 서로 코드를 이해하기 쉬울것이라 생각해서 선택했다.
하나의 비지니스 로직을 module에 담아 이해하기 편하며, 다른곳에서도 쉽게 import 해서 사용할 수 있다.
구조는 보편적으로 사용하는것처럼 Req -> Controller -> Service -> Repository -> DB 으로 사용했으며 ORM은 prisma를 사용했다. 이 프로젝트 할 때 제일 중점적으로 생각했던게 빠른시간안에 개발하면서 최대한 오류없게! 여서 틀이 정해진 것들을 쓰려고 했었다. 그래서 TypeORM과 달리 type-safe 한 prisma를 사용했다.
여러 비지니스 로직들을 정리하면서 API를 설계했다.
그 중 하나를 적어보면 이미지 기반 처리라서 추론기반 재고와 실제 재고를 어떻게 해야할까를 엄청나게 고민했었다. 입고 개념도 두개였다..
그래서 이미지를 찍을 때 마다 상태를 업데이트해서 현 상태를 파악하는 snapshot 과, 매장별로 들어온 상품의 수량을 수치로 파악하는 매장재고 stock 두개의 테이블을 만들었다. 결제가 이루어지면 이미지 기반 처리로 나간 상품의 카운트가 stock에서 깎이고 snapshot에는 마지막 사진 찍힌 이미지url과, 그 때 추론한 상황을 json으로 넣어준다. 추론의 정확도가 100%로가 아니기 때문에 이렇게 했다.
구매 비지니스 로직을 하나 예를들어 보면
1. 사용자가 상품을 구매한다.
2. 상품 추론 API 호출 (상품 Image -> 상품 ID array)
3. snapshot update (PUT /snapshot, body : SanpshotReqBody)
4. 결제 기록 생성 (POST /products, body : PurchaseReqBody)
AWS 인프라 구축
이제 AWS 인프라를 구축한다. 여러개의 시스템을 통째로 구축해보는건 이때가 처음이었다.
VPC에서 production 환경과 dev 환경을 나누어서 구축했다.
subnet과 route tables 구성도 해보았다.
private subnet으로 외부와 차단시켜주어 NAT / ELB를 통해 접근 가능하게 한다.

service api server는 도커로 말아서 ECS에 올려두었다. 서버리스 Fargate 사용했다.
DB는 Aurora DB를 사용했는데, ssh tunneling으로 local pc에서 접속 시 public ec2를 통해 private db 에 도달할 수 있게 만들었다.
관리자페이지는 모두 그렇게 하듯 s3 + cloudfront 로 배포! 프론트엔드 정적 콘텐츠 배포에는 굳이 돈 쓸 필요 없이 s3도 충분하기 때문. 그리고 Cloudfront를 사용하면 CDN (전 세계 엣지 로케이션에 자원 캐싱) 으로 s3만 사용할 때 보다 속도가 빨라진다.
인식 서버도 처음에 dokerizing 해서 ECS로 올렸는데 문제가 발생했었다.
무중단 배포가 되지 않는것이다...!!
그래서 살펴보니 해당 서버는 GPU를 필요로해서 GPU instance 로 컨테이너를 실행했는데 GPU가 1개 달린 인스턴스였다. (GPU 너무 비싸 ㅠ) 무중단 배포가 되려면 새로 task를 올렸을 때 기존 task가 실행 되고 있고 새로 띄운 task를 실행 시키고 healthcheck 후에 정상이면 기존 task를 지우고 새로운 task를 유지하는데 그 찰나의 순간에 GPU가 2개가 필요해져서... 무중단 배포가 되지 않는것이었다. task별 최소 할당량도 GPU1이라 어쩔 수 없는 상황이 생겨버렸다. 그래도 이유를 알아내서 속시원했다. (이렇게 써놓고 지금 보면 당연한데 그땐 한참 찾아서 발견함)
서버와 웹페이지들은 github에 push 하면 자동으로 배포가 되도록 github Actions로 CI/CD를 걸어두었다.
Outro
이 외에도 C#으로 키오스크 프로그램 만들기, 관리자 페이지 설계 및 개발, 전시회 준비 등 스팩타클했던 글 쓸 거리가 많지만 우선은 여기까지! 아마 다음편은 전시회 준비와 후기가 될듯
'🌀Full-Stack&Beyond' 카테고리의 다른 글
| 🐳 Docker 네트워크 충돌 문제 및 해결 방법 (네트워크 개념을 곁들인) (0) | 2025.02.26 |
|---|---|
| 네트워크 기초 완벽 정리: 패킷, 라우팅, 게이트웨이, 네트워크 인터페이스 (0) | 2025.02.26 |
| 서브넷 마스크와 네트워크 대역 쉽게 이해하기 (0) | 2025.02.26 |
| 인터넷에 www.naver.com을 입력하면 무슨 일이 일어날까? 🌍 (0) | 2025.02.23 |
| AWS 서비스를 On-Premise 환경으로 마이그레이션하기 (0) | 2025.02.22 |