
쿠버네티스(Kubernetes)는 컨테이너화된 애플리케이션을 자동으로 배포하고, 관리하며, 확장할 수 있도록 돕는 시스템이다.
클러스터 환경에서 여러 개의 컨테이너를 효율적으로 운영하려면 쿠버네티스의 내부 구조와 동작 방식을 이해하는 것이 중요하다.
이번 글에서는 쿠버네티스가 실제로 어떻게 동작하는지 차근차근 살펴보겠다.
📌 컨테이너 오케스트레이션이란?
컨테이너 오케스트레이션(Container Orchestration)은 여러 개의 컨테이너를 자동으로 배포, 관리, 확장하는 기술이다.
💡 왜 필요할까?
하나의 컨테이너만 실행하는 경우라면 크게 어렵지 않다.
docker run -d -p 8080:80 my-app
하지만,
- 수십 개~수천 개의 컨테이너를 운영해야 한다면?
- 컨테이너가 갑자기 종료되면 자동으로 다시 실행해야 한다면?
- 트래픽이 많아질 때 컨테이너 개수를 자동으로 늘려야 한다면?
- 특정 컨테이너가 죽으면 자동으로 교체해야 한다면?
이 모든 것을 수동으로 관리하는 것은 비효율적이다.
그래서 쿠버네티스(Kubernetes) 같은 오케스트레이션 도구가 필요하다.
✅ 컨테이너 오케스트레이션이 하는 일
- 컨테이너 자동 배포 및 시작
- 컨테이너 장애 감지 및 복구 (자동 재시작)
- 로드 밸런싱 (트래픽 분배)
- 자동 확장 (스케일링)
- 네트워크 및 서비스 관리
📌 클러스터란?
클러스터(Cluster) 는 여러 대의 컴퓨터(서버)를 하나의 시스템처럼 동작하도록 묶은 것이다.
💡 왜 클러스터가 필요할까?
🚫 서버가 한 대만 있다면?
- 해당 서버가 다운되면 서비스 전체가 중단된다.
✅ 클러스터를 사용하면?
- 여러 개의 서버를 묶어 하나의 클러스터로 만들면 장애 대응, 확장성, 성능 개선이 가능하다.
- 쿠버네티스에서는 마스터 노드 + 여러 개의 워커 노드 가 모여 클러스터를 구성한다.
✅ 클러스터의 핵심 개념
- 확장성(Scalability) → 트래픽이 늘어나면 더 많은 노드를 추가하여 부하를 분산
- 가용성(Availability) → 특정 노드가 죽어도 다른 노드에서 서비스가 유지됨
- 자동화(Automation) → 컨테이너 배포, 스케일링, 장애 복구가 자동으로 이루어짐
📌 노드란?
노드(Node)는 클러스터를 구성하는 개별 서버(컴퓨터) 를 의미한다.
쿠버네티스에서는 두 가지 종류의 노드가 존재한다.
1️⃣ 마스터 노드 (Master Node)
- 클러스터를 관리하고, 워커 노드에게 명령을 내리는 컨트롤 타워
- API 서버, 스케줄러, 컨트롤러 매니저, etcd 등이 실행됨
- 쉽게 말해, "감독관" 역할을 한다.
2️⃣ 워커 노드 (Worker Node)
- 실제 애플리케이션이 실행되는 서버
- 컨테이너(Pod)를 실행하고 관리하는 역할
- Kubelet, kube-proxy, 컨테이너 런타임(Docker 등)이 포함됨
- 쉽게 말해, "실제 작업을 수행하는 일꾼" 역할을 한다.
💡 정리하자면, 노드는 클러스터를 구성하는 개별 서버이고, 마스터 노드가 전체를 관리하며, 워커 노드에서 실제 애플리케이션이 실행된다.
1. 쿠버네티스의 기본 구조
쿠버네티스는 크게 마스터 노드(Master Node) 와 워커 노드(Worker Node) 로 구성된다.
마스터 노드는 클러스터를 관리하고, 워커 노드는 실제 애플리케이션이 실행되는 곳이다.
각 노드는 역할이 다르지만, 서로 유기적으로 연결되어 컨테이너를 안정적으로 운영할 수 있도록 한다.
2. 마스터 노드(Master Node)에서 하는 일
마스터 노드는 쿠버네티스 클러스터의 컨트롤 타워 역할을 한다.
애플리케이션을 실행하거나 관리할 때, 모든 요청이 마스터 노드를 통해 이루어진다.
📌 API Server (API 서버)
API 서버는 쿠버네티스의 핵심 인터페이스다.
- kubectl과 같은 명령어를 실행하면 API 서버가 요청을 받는다.
- 클러스터에서 일어나는 모든 일은 API 서버를 통해 이루어진다.
- 쉽게 말하면, 쿠버네티스의 "입구" 같은 역할을 한다.
📌 Scheduler (스케줄러)
스케줄러는 새로운 Pod(파드) 가 생성될 때, 어디에서 실행할지를 결정한다.
- 각 노드의 CPU, 메모리 상태 등을 고려하여 최적의 노드를 선택한다.
- 예를 들어, 특정 노드의 부하가 크다면 다른 노드로 Pod을 배치한다.
- 택배를 보낼 때 가장 빠른 경로를 찾는 내비게이션과 같은 역할을 한다.
📌 Controller Manager (컨트롤러 매니저)
Controller Manager는 클러스터 상태를 지속적으로 감시하고 조정하는 역할을 한다.
- “원래 3개의 Pod이 있어야 하는데 1개가 죽었네? 다시 만들어야겠다.”
- 이런 식으로 클러스터가 항상 정상적인 상태를 유지하도록 관리한다.
📌 etcd (데이터 저장소)
etcd는 쿠버네티스의 데이터베이스다.
- 클러스터의 모든 정보를 저장하는 곳이다.
- API 서버가 요청을 받으면 etcd에 기록하고, 현재 상태를 업데이트한다.
3. 워커 노드(Worker Node)에서 하는 일
워커 노드는 애플리케이션이 실제로 실행되는 공간이다.
마스터 노드에서 "여기서 실행해!" 라고 명령을 내리면, 워커 노드는 이를 수행한다.
📌 Kubelet (쿠블렛)
Kubelet은 API 서버의 지시를 받아 컨테이너를 실행하는 역할을 한다.
- Pod을 생성하고, 컨테이너가 정상적으로 동작하는지 체크한다.
- 쉽게 말하면, "일꾼" 같은 역할을 한다.
📌 kube-proxy (쿠브-프록시)
kube-proxy는 네트워크 트래픽을 관리하는 역할을 한다.
- 외부에서 들어오는 요청을 적절한 Pod으로 연결한다.
- 예를 들어, 사용자가 http://my-app.example.com 에 접속하면 kube-proxy가 해당 요청을 적절한 Pod으로 전달한다.
📌 Pod (파드)
Pod은 쿠버네티스에서 애플리케이션을 배포하는 최소 단위다.
- 하나의 Pod 안에는 하나 이상의 컨테이너가 들어 있을 수 있다.
- 같은 Pod 안의 컨테이너는 네트워크와 볼륨을 공유한다.
4. 쿠버네티스의 실제 요청 흐름
쿠버네티스에서 애플리케이션을 배포하는 과정을 단계별로 하나씩 따라가 보자.
🚀 Step 1: 개발자가 kubectl 명령어 실행
개발자가 새로운 애플리케이션을 배포하고 싶다고 가정하자.
터미널에서 다음 명령어를 입력한다.
kubectl apply -f my-app-deployment.yaml #YAML 파일에 정의된 쿠버네티스 리소스를 클러스터에 적용하는 명령어- 이 명령어는 API 서버로 전달된다.
- API 서버는 "이 요청이 맞는지?"를 확인한 후 etcd에 기록한다.
- 쉽게 말해, "새로운 애플리케이션을 실행해야 한다!" 는 내용이 저장된다.
🚀 Step 2: 스케줄러가 실행될 위치 결정
API 서버가 요청을 받았으니, 이제 어디에서 실행할지 결정할 차례다.
- 스케줄러가 클러스터 내 노드들의 리소스 상태를 확인한다.
- CPU 사용량이 높은 노드는 피하고, 적절한 워커 노드를 선택한다.
- 쉽게 말해, "어떤 워커 노드가 가장 적합할까?" 고민하는 단계다.
🚀 Step 3: 워커 노드에서 Kubelet이 Pod 실행
스케줄러가 선택한 워커 노드에서 Kubelet이 Pod을 실행한다.
- Kubelet이 API 서버의 지시를 받아서 컨테이너 런타임(Docker 등)에게 “이 컨테이너를 실행해라” 라고 명령한다.
- Docker가 컨테이너를 실행하면, 애플리케이션이 실제로 실행된다.
🚀 Step 4: kube-proxy가 네트워크 연결 설정
애플리케이션이 실행되었지만, 외부에서 접근하려면 네트워크 설정이 필요하다.
- kube-proxy가 트래픽을 적절한 Pod으로 라우팅한다.
- 예를 들어, http://example.com 으로 요청이 들어오면 kube-proxy가 적절한 Pod으로 연결해 준다.
- 즉, "트래픽이 올바른 Pod으로 전달될 수 있도록 길을 만들어 준다."
그림으로 정리해봄
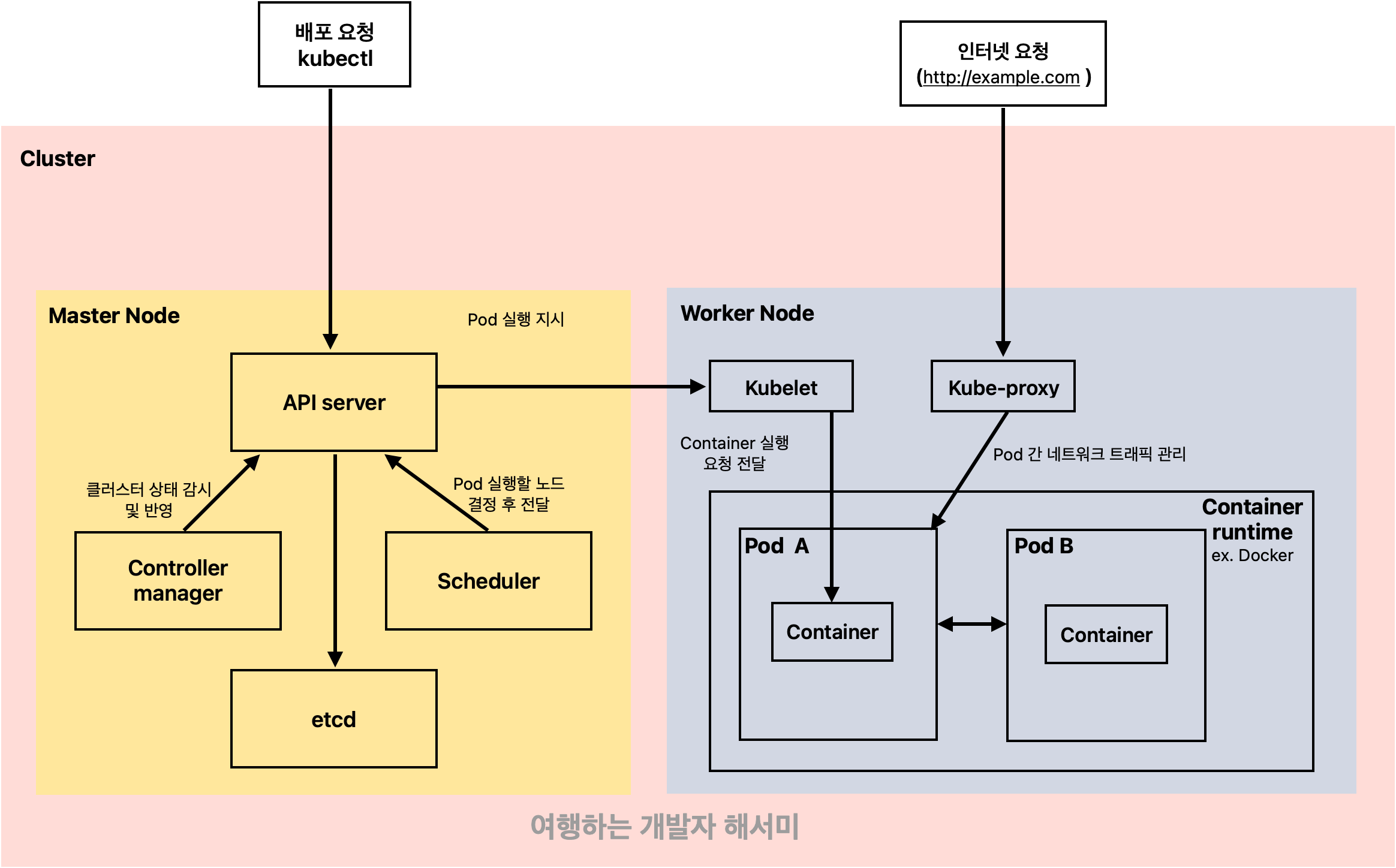
5. 마무리: 쿠버네티스를 쉽게 이해하는 방법
쿠버네티스를 이해하려면 각 요소의 역할을 현실적인 비유로 생각해보자.
✔ 마스터 노드 → 감독관
- 클러스터 전체를 관리하고 명령을 내린다.
✔ 워커 노드 → 일꾼
- 마스터 노드의 명령을 받아 실제로 애플리케이션을 실행한다.
✔ API 서버 → 쿠버네티스의 뇌
- 모든 요청이 API 서버를 통해 이루어진다.
✔ 스케줄러 → 내비게이션
- 가장 적합한 워커 노드를 선택한다.
✔ Kubelet → 현장 작업자
- 직접 컨테이너를 실행하고 관리한다.
✔ kube-proxy → 네트워크 관리자
- 외부 트래픽을 올바른 Pod으로 연결한다.
이제 쿠버네티스가 어떻게 동작하는지 감이 잡혔을 것이다.
다음 글에서는 쿠버네티스를 활용한 실제 배포 및 운영 방법에 대해 더 깊이 다뤄보겠슴당
'🌀Full-Stack&Beyond' 카테고리의 다른 글
| 도커 Nginx 환경에서 logrotate를 활용한 자동 로그 관리 방법 (0) | 2025.02.27 |
|---|---|
| 🐳 Docker 네트워크 충돌 문제 및 해결 방법 (네트워크 개념을 곁들인) (0) | 2025.02.26 |
| 네트워크 기초 완벽 정리: 패킷, 라우팅, 게이트웨이, 네트워크 인터페이스 (0) | 2025.02.26 |
| 서브넷 마스크와 네트워크 대역 쉽게 이해하기 (0) | 2025.02.26 |
| 인터넷에 www.naver.com을 입력하면 무슨 일이 일어날까? 🌍 (0) | 2025.02.23 |